A Step by Step Guide to MongoDB for .NET Developers

During DDD8 I attended Neil Robbins "Hello Document Database" talk, where he demo'd how to get started with CouchDB. Although I have heard a lot about the NoSQL movement - this was the first time I had seen a document database in action. In the last 12 months I've been spending a lot of time with search technologies such as Lucene and Solr (which have recently merged into one project), so the idea of storing data in a repository other than a relational database has been in the forefront of my mind for a while.
2009 - the year ORM's went mainstream
For .NET Developers 2009 was the year that many made the leap from working with relational data via SQL & Stored Procedures to using an Object Relational Mapper (ORM) Framework such as NHibernate or Entity Framework. This is a great leap to make as it can massively reduce the development, deployment and maintenance burden - because using an ORM means you have essentially excised a whole layer of your application architecture. This generally throws DBA's into cataleptic fits because by using an ORM you are eroding away their speciality and they will generally throw performance, security & reliability arguments into the mix, but realistically for 99.99% of standard CRUD operations an ORM is a much better solution to hand cranked SQL.
The problem with ORM's is the fundamental impedance mismatch between Object Orientation and Relational Databases – not only do you have to design each model adhering to the optimal rules of both domains but then you have deal the fundamental differences between deep object graphs and relational data; the best manifestation of this is the pain of mapping files - the bane of any NHibernate user's life. This is one area where the "convention over configuration" mantra comes into its own and products like Fluent NHibernate makes this process easier - although not entirely pain free.
2010 - the year of NoSQL and Document Databases?
This is where the NoSQL movement and in particular document databases hit the sweet spot. If you've been following the latest trend of conversations about scaling web applications for a global audience - you generally wont hear relational databases being mentioned because relational databases don't scale well (there's a reason why SQL Server Azure allows a max db size of 10 Gb). When companies like Twitter & Digg talk about their future plans you hear far more exotic names that "Microsoft SQL Server 2008 R2" - you hear product names such as RavenDB, Cassandra, Voldemort, MemcacheDB, Redis, HyperTable and the aforementioned CouchDB.
One of the major pain points of using a standard relational database is not just the schema design, but all the problems associated with updating and versioning of the schema. Making schema changes on systems that have brittle architectures is the bane of the lives of the developers working on those systems. Because these document databases are schemaless (or rather they provide dynamic-schemas) - you do not face the same problems. You are free to modify the documents you store, they can be irregular and have different properties - the problem might be moved up a level where you convert the documents into your domain objects. If you are using dynamic languages you may have to ensure that the properties you access actually exist and add extra error handling to deal with this edge case. In any case this is much less of a burden than standard schema versioning hell.
One niche that document databases fit into exceedingly well is the CQRS pattern that is growing in popularity. If to provide scale and speed for your web architecture you decided to create View Model repositories so that you can quickly and easily populate your UI with data using an efficient Select * rather than performing traditionally expensive and slow relational queries with multiple joins, then document databases offer a very compelling solution. They are high performance, efficiently store data, they have built in support for replication and auto fail over, they are open source and run on Windows & *nix platform, thus can be cheap to scale and also support auto-sharding if you require cloud-level scalability and finally they have dynamic schemas so your development & maintenance effort is minimal.
The more I learn about Document Databases and in particular CouchDB and MongoDB - they more I understand that these are products of the web and by the web. Not only do they solve traditionally hard web problems such as scale but they also use web technologies at their core; MongoDB uses JavaScript in its Shell as well as internally for some Map Reduce functions and CouchDB uses a RESTful JSON API which allows you to query it directly from HTTP - which means you can query the database directly from your browser, which is very powerful if you want to perform fast AJAX read operations. With MongoDB you can query and receive results in a JSON like format (BSON) that any web developer should be familiar with.
CouchDB vs. MongoDB
I started investigating CouchDB - mainly because of Neil's demo - but after doing a little research on the ecosystem - I stumbled across this blog post about CouchDB vs. MongoDB - and it was at this point I discovered that CouchDB can't do dynamic queries - which is a pretty essential feature for me as I like to be able to easily explore the data. At this point I swapped focus and started to dig a little deeper into MongoDB and have to say that I really like what I've found.
The main problem that I discovered trying to get started with both CouchDB and MongoDB is that document databases really work well when they are accessed viaa dynamic language. The real problem is that using them via a static language, means you have to deal with data in the form of a dictionary. This just isn't acceptable. Scott Watermasysk has a nice post on a potential work around combining the MongoDB-CSharp Driver and C#4's dynamic keyword to replicate the behaviour in most dynamic languages.
NoRM - Making MongoDB mainstream for .NET Developers
At this point I discovered a new attempt to create a C# Driver for MongoDB that would allow seamless POCO conversion and LINQ support. The project is called NoRM and it's the best hope for making MongoDB mainstream for the .NET Community. They guys working on the project are Andrew Theken, Rob Conery (the guy behind SubSonic and TekPub), Karl Seguin, James Avery, Jason Alexander, Olivier Oswald, Nate Kohari, Steve Mason and a few others. NoRM is incredibly simple to get started with and I've put together a small demo that you can play with.
Getting Started with MongoDB and NoRM
On a slight tangent - one of the great initiatives that the UK government has kicked off in the last few months is http://data.gov.uk, led by Sir Tim Berners-Lee, it is a program of work to open all the data of the UK Government, data that we, as tax payers have paid for and should be allowed access to. For developers - this is a treasure trove of novel "real" data with which we can play with. For this demo I picked an XML feed that contains information sports clubs in the district of Lichfield.
Firstly I created a self-contained solution that has everything you need:
You can download this package from the endjin git repository.
Step 1: Get MongoDB up and running
Extract the package (or pull) to C:\Projects\OpenSource then navigate to C:\Projects\OpenSource\StepByStepGuideToMongoDB\Tools\MongoDB in this folder you should see 2x .exe files, 2x .cmd files and 3 readme files.
The two .exe files are MongoDB's client and server applications. Double click start-mongod-(the-server).cmd - this is a custom command file which starts the MongoDB Server and pipes in a configuration setting to specifically set the path where MongoDB stores it's data files to C:\Projects\OpenSource\StepByStepGuideToMongoDB\Data\MongoDb
Once you run the cmd file you should see the following Command Prompt window:
You may be presented with a Windows Firewall dialog - dismiss this.
If you want to access the web admin interface (it's a bit sparse!) you can via http://localhost:28017 (as mentioned in the last line of text in the command prompt).
If you navigate to C:\Projects\OpenSource\StepByStepGuideToMongoDB\Data\MongoDb you will notice this folder is empty - the database is running but we haven't imported any data yet.
Step 2: Run the Solution
Open the Solution file located at: C:\Projects\OpenSource\StepByStepGuideToMongoDB\Solutions\StepByStepGuideToMongoDB.sln - this is a VS 2010 RC solution file. Once you've opened the solution file - there are only 4 files that you really need to look at:
- /Program.cs - this is where the main logic sits
- /Infrastructure/DataSources/RemoteClubDataSource.cs - this pulls down the XML Feed and uses LINQ to XML to convert it into a POCO
- /Framework/Infrastructure/Norm/Session.cs - this wraps NoRM and the calls to MongoDB
- /Contracts/Framework/Infrastructure/Repositories/IUniqueIdentifier.cs - this is an interface that defines an Id Property required for MongoDB Updates.
I borrowed the Sessions.cs file from the NoRM unit test project which uses it as the default method for performing integration tests - I made one small adjustment as a workaround for a bug I discovered, which you can see on line 55:

While working on the demo I discovered that calling the UpdateOne method using the (item, item) signature didn't actually update the item in MongoDB and that instead you need to provide a MatchDocument (essentially an criteria document that allows you to specify which document in the document database will be updated). To make this work I had to modify the generics constraints to require that the Type implements IUniqueIdenfitierwhich means we have access to the Id property in order to construct the MatchDocument. IUniqueIdenfitier.cs is as follows:

ObjectId is a NoRM type that represents a MongoDB ObjectId, which is is a 12-byte value consisting of a 4-byte timestamp, a 3-byte machine id, a 2-byte process id, and a 3-byte counter.
Finally it all comes together in Program.cs, where we retrieve the feed, convert it into POCO, insert all the clubs into a new collection called "Club" and perform a LINQ query against the MongoDB database collection for a club that has a Contact with a specific name, we then update that club's telephone number, update and re-query, again using LINQ, to ensure that the update was successful.

Hit F5 to run the project for yourself.
Once you run the the solution you will see the following window appear showing the data we have parsed & inserted into the document database, queried, updated and re-queried:

If you swap to the MongoDB Server Window you can see there has been activity:

You can see the following has happened:
- The server has accepted an incoming connection
- It has build a new index for the Database called "ClubDocDB" and the collection called "Club"
If you navigate to the data directory - *C:\Projects\OpenSource*
StepByStepGuideToMongoDB\Data\MongoDb - you will see that this has now been populated by two data files:
- ClubDocDB.0 (64mb)
- ClubDocDB.ns (16mb)
These files are preallocated - just in case you thought we had processed and indexed80 mb of data. See the MongoDB FAQ for more info on data files.
Step 3: Using the MongoDB Shell
I've shown how you can access MongoDB via NoRM - it's stupidly easy - if you are running MongoDB on your local machine then configuration is minimal - all you need to do is specify the document database name you want to connect to. Your collection name is based on the name of the POCO entity you specify. There is another way to connect to MongoDB - via the MongoDB Interactive Shell.
Navigate to C:\Projects\OpenSource\StepByStepGuideToMongoDB\Tools\MongoDB and double click on start-mongo-(the-client).cmd - this will launch the MongoDB Shell:

To view the databases you can use the following command:
show dbs
To access the database you have just created enter the following command:
use ClubDocDB
This switches to our database. Next you can view the collections under this database using the command:
show collections
You should see the following results:
Clubsystem.indexes
Next we can actually query the collection in the same we queried it using NoRM and LINQ but using the native query syntax:
db.Club.find({ "Contact.Name" : 'Daryl Loynes' })
The results of this query are returned to the shell as BSON (binary-encoded serialization of JSON-like documents):

This is quite impressive as the field we queried is actually a sub-property of the document we indexed. This is really part of the magic of MongoDB in that the document as a whole is stored in the data file as BSON and the query language understands that we are querying complex objects rather than rows and columns. The query language supports this "dot notation" which allows us to reach inside documents and query it; this is extremely powerful.
We can perform a more fine-grained query and specify that we only want to return the Tel field:
db.Club.find({ "Contact.Name" : 'Daryl Loynes' }, { "Contact.Tel" : 1 })
This will return the following BSON result:
{ "Contact" : { "Tel" : "555-123-456" }, "_id" : ObjectId("4cdefa02b6f5465017110000") }
You can see that the result also provides us with an _id field which we could use if we wanted to change the Tel field value and apply this back as an update. For more information on querying have a read of the documentation.
For more information on the MongoDB Shell - have a read of the documentation.
Step 4: Using MongoVUE
As much fun as typing complex data structures into a command line is, a nice GUI makes any technology seem less scary. Luckily for us MongoVUE exists and provides a very pleasant SQL Management Studio like experience over MongoDB
First download and install MongoVUE.
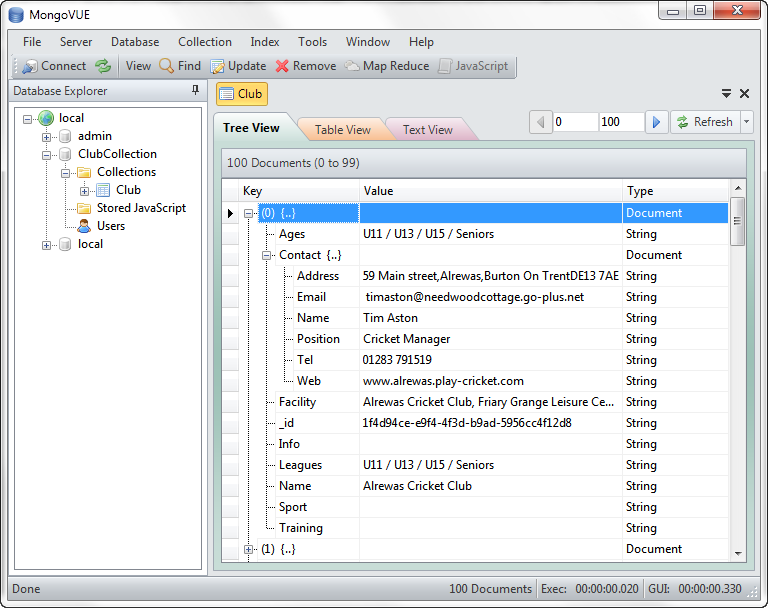
Next, run MongoVUE and connect to the default "local" connection. Once connected you should see a ClubCollection note which contains a Collection called Club. If you double click the Club node a table view will be rendered, expand the first document to see its data:
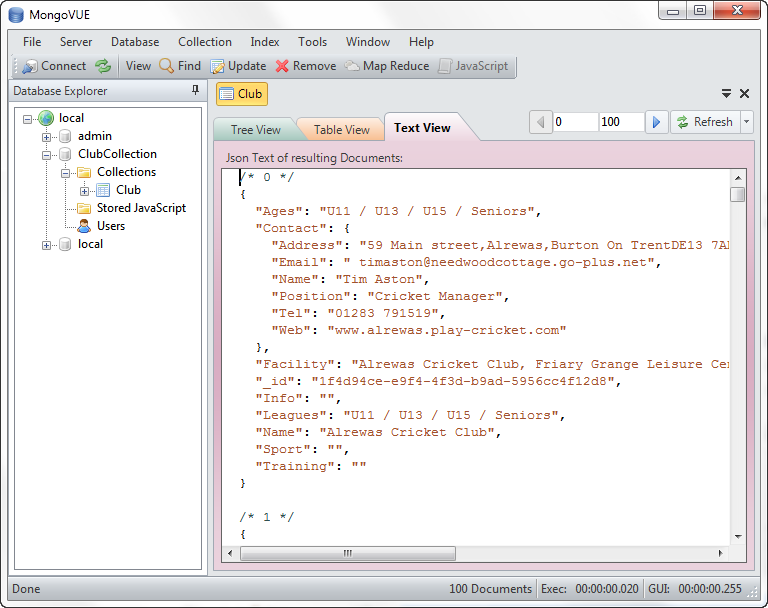
Or click Text View to see the raw document:
Next we'll repeat the earlier search command we executed via command line. First click on the "Find" icon on the toolbar. This will display a new search interface:

next paste the following into the field:

and click the "find" button. You should see two results:

MongoVUE has far more features than can be described in this blog post – if you are interested in learning more of its features, read through its tutorials.
If this post has got you interested in MongoDB, why not spend 10 minutes using the interactive demo / mini tutorial of MongoDB at: http://try.mongodb.org/
Finally, for a broader overview of MongoDB and it's features, I strongly recommend reading this presentation:
Work smarter, not harder.
@HowardvRooijen | @endjin