A code review with NDepend Part 1: Quality metrics


Over the years we've built a lot of IP up here at endjin. With a growing codebase, and with my training shifting to look at software architecture, I thought I'd attempt a code review to see what insight I could gain!
So... Here goes nothing!
The tool I chose to carry out this review is NDepend, it is an extremely powerful means of investigating codebases (of all sizes, but was particularly useful in providing insight into our rather ungainly one). But before I dive into a description of the process and value gained when using the tool, I first want to outline how it measures quality.
NDepend's analysis is mainly based on defining rules surrounding different metrics which indicate code quality. The rules around the thresholds and formulae used are entirely customisable (you can even define your own!). But, here are the main built in ones, along with their default values:
General metrics
These are metrics which span multiple levels (fields, methods, types and assemblies) within your code.
Percentage comment
This is the percentage of your code which consists of comment. The default is that if your code is <20% comment, more is needed, and that >40% is excessive.
Percentage coverage
This is the percentage of your code which is covered by tests and is imported from coverage files. There is no hard and fast rule on this. A good amount of your code should be covered, however the coverage data usually only takes into account those tests which are automated as part of a build. You can also run into a point of diminishing returns, where the effort of more coverage is not justified by the benefits.
Afferent coupling
Afferent coupling is the number of external things depending upon you. Ideally things with high afferent coupling are small and stable because making changes is very likely to break something elsewhere.
Efferent coupling
This is the number of external things you depend upon. High efferent coupling indicates that a class is probably doing more than it should. The more dependencies something has, the more likely it is to break when something changes.
Cyclomatic complexity
This is used to measure the number of independent paths there are through a method/type. (This is measured by counting if/else/while/for/etc statements)
In general if a type has >15 it is hard to understand, >30 is extremely complex and you should take a look at it and consider splitting the logic into smaller chunks.
Metrics on methods
These are metrics which generally apply to the methods within your code:
Lines of code (LOC)
This sounds fairly self-explanatory, but the metric that NDepend uses is actually the "Logical LOC", which is computed from PDB sequence points (PDB files are created when you compile code and relate to the logical steps in that code). This means that the LOC metric is independent of language and (aesthetic) coding style. Interfaces, abstract methods and enums also all count as 0 lines of code.
The default metric states that any method with >20 LOC is hard to understand, and any with >40 is extremely complex and should perhaps be split.
Number of parameters
Generally, if a method has >5 parameters it is hard to call and can impact performance.
Number of variables
Generally, if a method has more than 5 variables it is hard to understand, more than 8 is very complex.
Number of overloads
More than 6 overloads to a method makes it hard to maintain and can indicate high coupling.
Metrics on types
Here are the ones which are mainly applicable to types:
Number of methods/fields
Types with >20 of each methods or fields are hard to understand, however in many cases it is impossible to avoid such types.
Lack of method cohesion
This measures to what extent the methods in a class act towards a single responsibility. I.e. measures the amount of interrelation between the methods.
The easier way to measure this is using the LCOMHS (Lack of cohesion of methods – Henderson-Sellars). It is based on the number of methods in a class, the number of fields and the number of methods accessing a particular instance field. It takes values between 0 and 2.
Types where LCOM HS > 1, and # Methods and # Fields >10 should be avoided where possible.
Size of instance
Large instances can degrade performance, depending on their quantity and life cycle. However, these large instances are sometimes unavoidable.
Depth of inheritance tree
An inheritance tree with a depth ≥6 can be hard to maintain.
Metrics on assemblies
And the ones which are relevant to assemblies:
Relational cohesion
The internal relationships per type. Something in an assembly should be strongly related to the rest of that assembly. A value of 1.5 to 4 is ideal.
Instability
Instability is the ratio of efferent to total coupling. This indicates the technical difficulty to change things.
A high instability (high efferent compared to total coupling) means that there is not much depending on the assembly, so change is easy. It also indicates that it may be liable to break if something changes in one of its large number of dependencies, so change may be necessary.
An assembly with low instability (so a stable assembly) does not have much dependence on external assemblies, so is unlikely to break due to dependency changes (so is unlikely to need to change). However, it has many external things depending on it, so any change is difficult to implement.
Ideally something should either be extremely unstable (so change and refactoring is easy) or extremely stable (so change and refactoring is unnecessary). As a rule, you should only take dependencies on things more stable than yourself.
Abstractness
The number of abstract types compared to total types.
Normalised distance from main sequence
D = |A + I – 1|
This indicates the balance between abstractness and stability. "Ideal" assemblies are completely abstract (A=1) and stable (I=0) (i.e. an assembly of interfaces with no outer dependencies), or completely concrete (A=0) and instable (I=1) (everything is independent and changeable).
So ideally D=0, and anything over 0.7 will be problematic. However, in practice there many assemblies which necessarily break this rule.
Namespaces
The final thing to mention is the rules around namespaces. Namespaces are given levels depending on namespaces that are used within it, and the level of those namespaces. A level of 0 means that no other namespaces are used, otherwise the level is 1 + the highest level of a namespace used. As levels increase, the complexity increases and the code gets harder to understand.
A level of N/A means that the namespace is involved in a dependency cycle, which it is recommended to avoid if at all possible.
NDepend's analysis
NDepend measures each of these metrics and collates a corresponding report on your code quality. For each one there is also a formula defined for the "technical debt" incurred by violating the defined rule (these formulae are also customisable). You are then presented with an explorable summary of your code quality and can drill down into various aspects of the analysis.
Here's a sneak peak of the kind of visual you get to support the analysis (methods analysed for cyclomatic complexity, size indicating LOC):
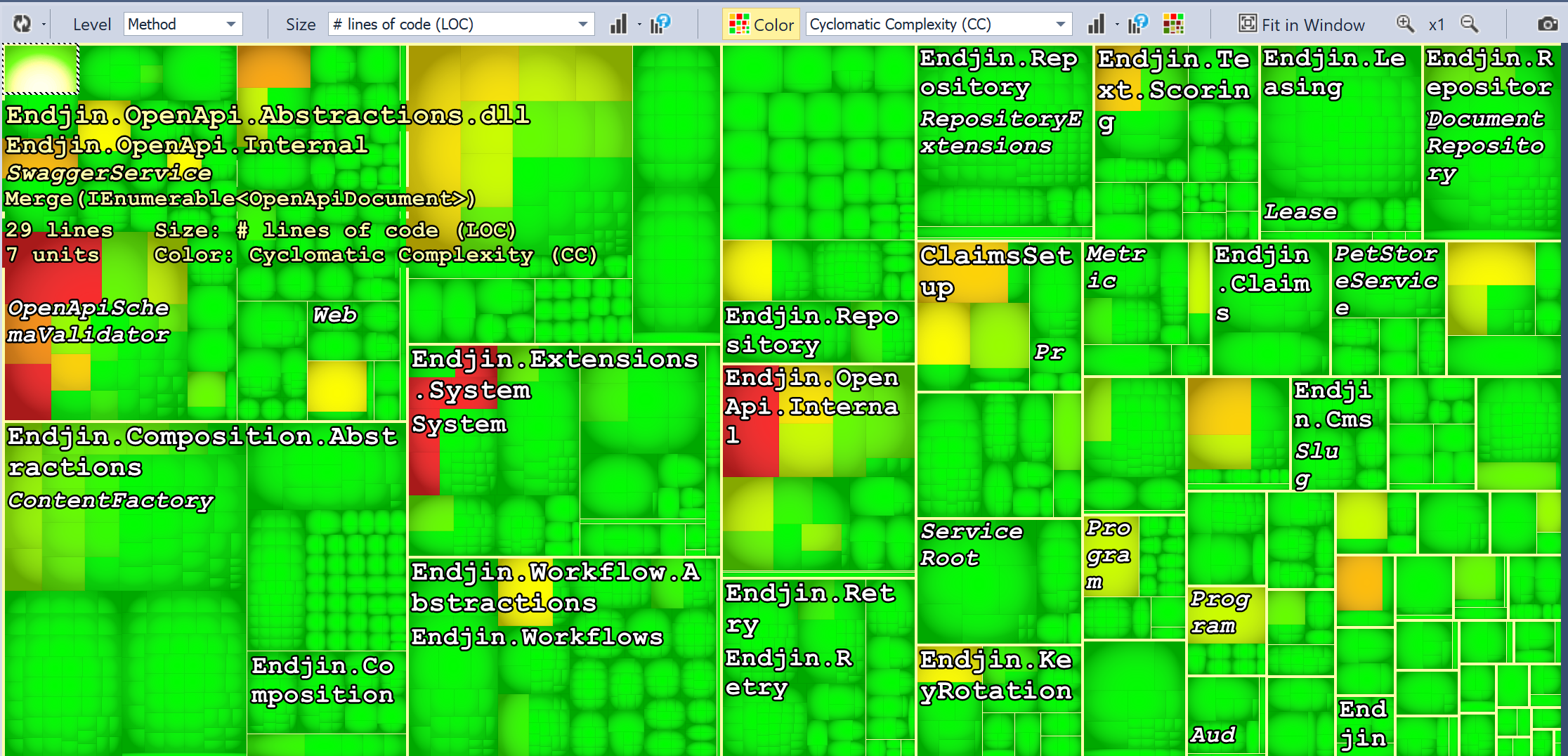
But more on that next time!



