Exploring Azure Data Factory - Mapping Data Flows

As part of a recent project we did a lot of experimentation with the new Azure Data Factory feature: Mapping Data Flows. The tool is still in preview, and more functionality is sure to be in the pipeline, but I think it opens up a lot of really exciting possibilities for visualising and building up complex sequences of data transformations.
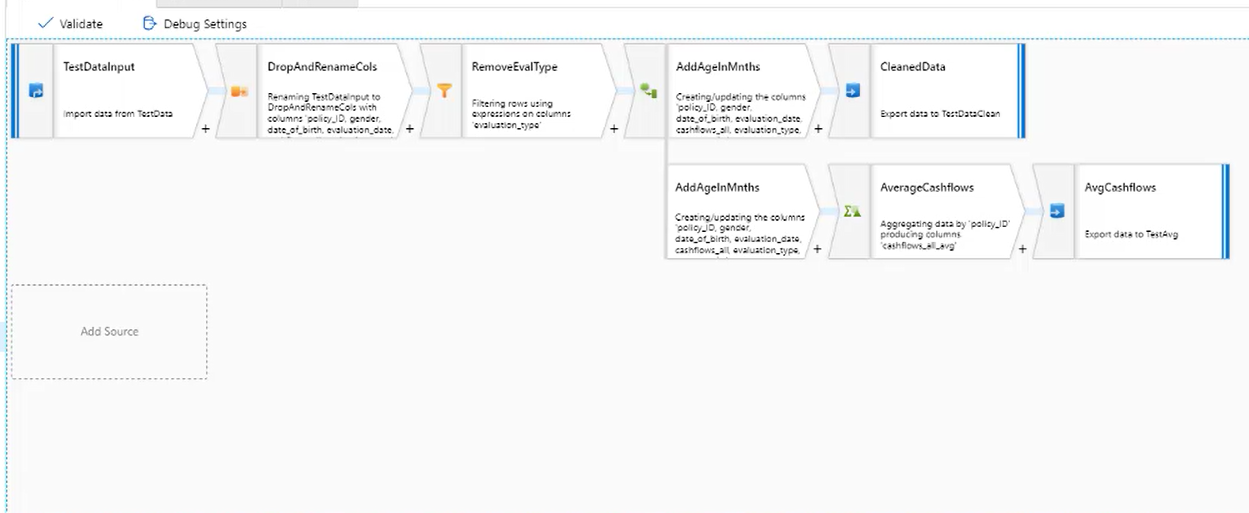
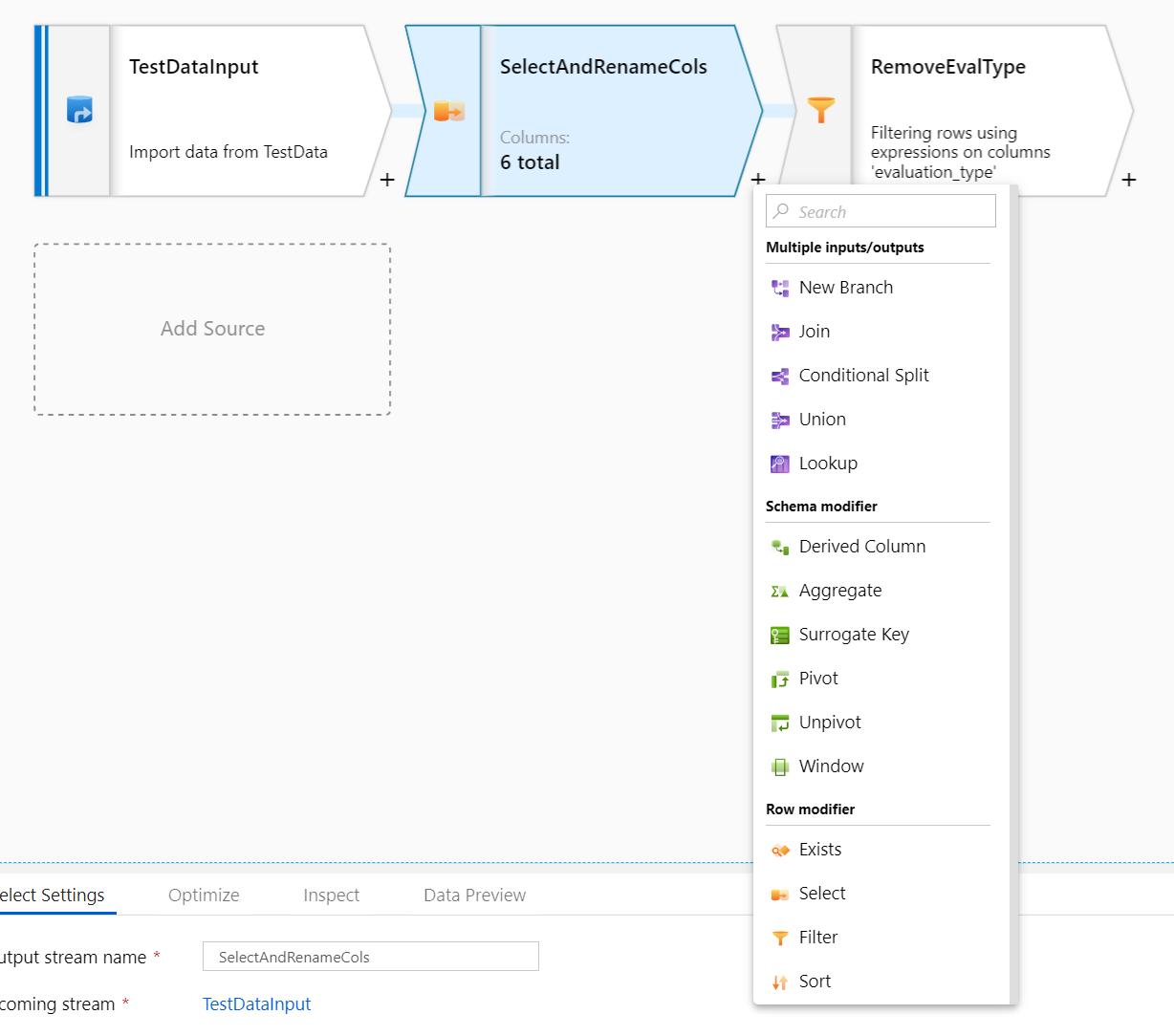
A Data Flow is an activity in an ADF pipeline. You define a data source and can then apply a variety of transformations to that data. Currently the supported data sources are Azure Blob Storage, ADLS Gen1 and Gen2, Azure SQL Data Warehouse and Azure SQL Database, with supported file types or CSV or Parquet. However, support for many other sources and file types is imminent. Once you have chosen a data source, you have the ability to filter rows, create derived columns, conditionally split and join sources, perform aggregations over the data and more. There is also the ability to extend the transformation options by building your own custom transformation in either Java or Scala.
By default Data Flow uses partitioning strategies which are optimised for your workload when running the flow as part of an ADF activity. However, you can also pick between a list of partitioning strategies, some of which may increase performance. The partitioning strategy for each individual step in the data flow can be edited, so some experimentation would be needed to find the best combination for each specific workload.
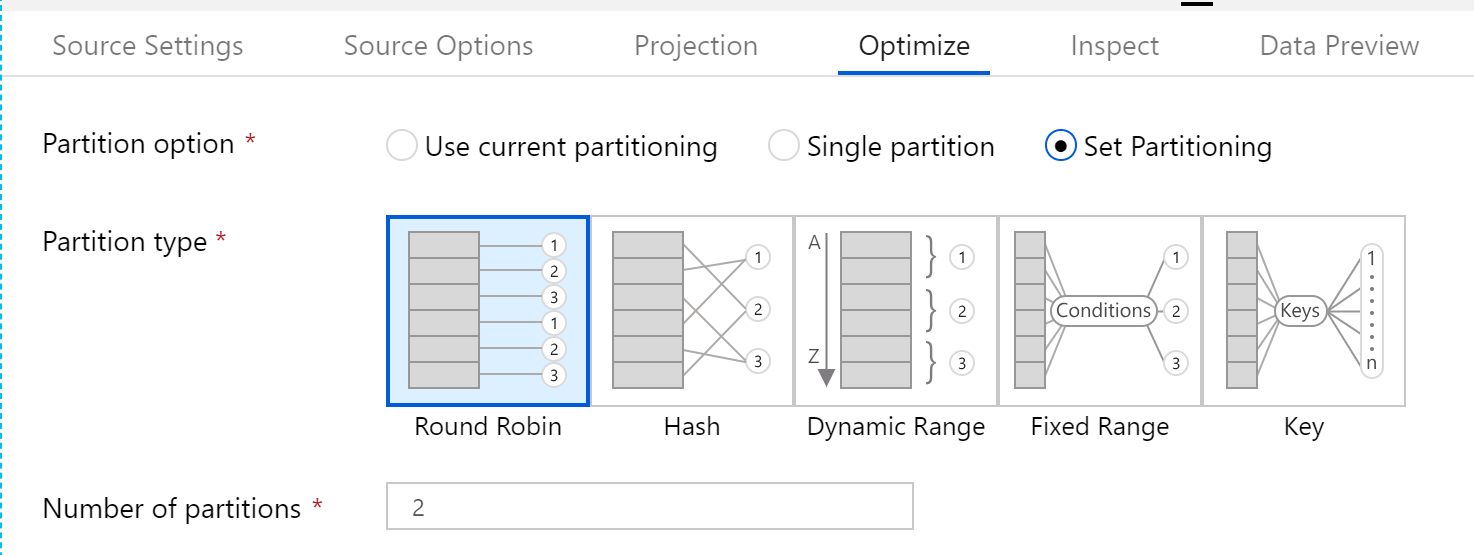
There is also good debugging support within Data Flows. You can run a set of sample data (of variable size) through the data flow and see the effect of your transforms. This means that as you author a data flow, you can quickly gauge the effect of any transformations applied, and catch errors in the processing.
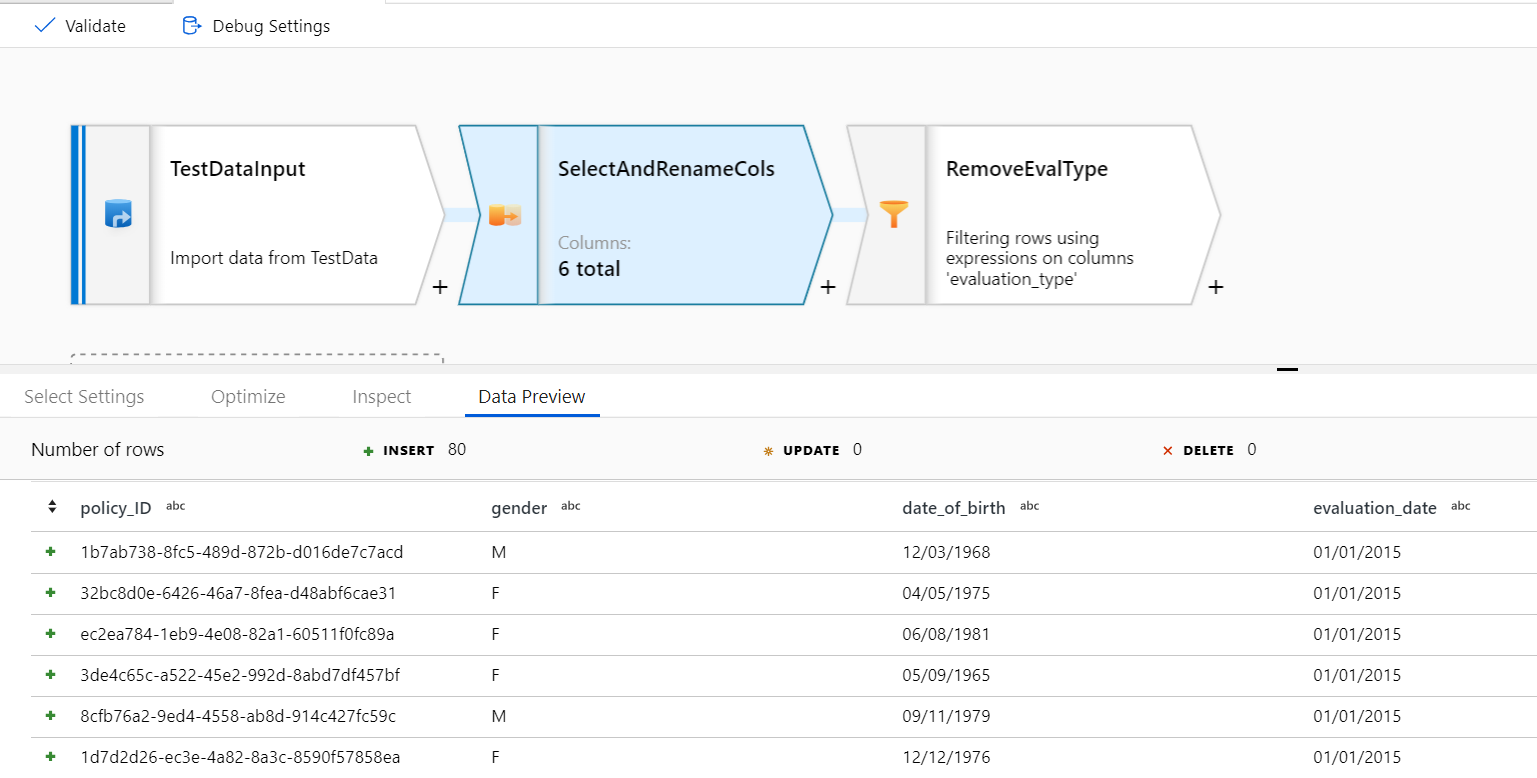
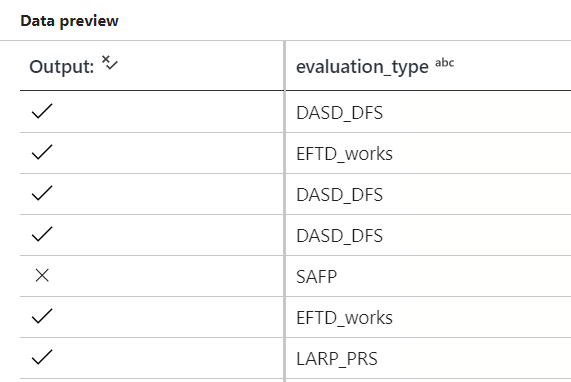
You can also use the debugger to see the effect of the individual transformations used when filtering/creating new columns. For example, filtering rows based on:
notEquals(evaluation_type, 'SAFP')
Produces the following debug output inside the filter expression editing pane:
Finally, once you have finished authoring a Data Flow, you are then able to export the representative code. This means Data Flows can be re-used and deployed as necessary. E.g. the first two transformations in the above Data Flow are represented like this:
"transformations": [
{
"name": "SelectAndRenameCols",
"script": "TestDataInput select(mapColumn(\n\t\tpolicy_ID = recordkey,\n\t\tgender,\n\t\tdate_of_birth,\n\t\tevaluation_date,\n\t\tcashflows_all,\n\t\tevaluation_type\n\t))~> SelectAndRenameCols"
},
{
"name": "RemoveEvalType",
"script": "SelectAndRenameCols filter(notEquals(evaluation_type, 'SAFP')) ~> RemoveEvalType"
}
]
Areas for improvement
We encountered a couple of issues during our experimentation. The first is that currently, the Data Flow is run on a Databricks cluster which is spun up for you when you run the activity in the ADF pipeline. This means that a significant portion of the activity duration is spent spinning up a new Databricks cluster, especially at smaller workloads. Hopefully once the feature moves out of preview, the option will be available to run the Data Flows in a BYOC (Bring Your Own Cluster) mode, enabling the use of already-warm interactive clusters, which would significantly reduce the execution time.
Secondly, there currently not adequate monitoring information given around either performance or pricing. The timings and row counts given at the end of a successful data flow activity seem inconsistent, and there is no apparent way of retrieving the cost of each job run. This makes it difficult to assess bottlenecks and more expensive sections of the Data Flow. However, again, this feature is only in preview so hopefully there are improvements coming in this part of the tool.
Overall
Despite the room for improvement, I think this is a powerful technology for enabling the use of simple data transformations to build up complex data manipulation pipelines. I hope to see it improve and grow as it matures, in order to aid the streamlining of data transform and ETL processes. And by extension, allowing improved data discovery and insights, without the need for writing code!