NDC London 2020 - My highlights


A couple of weeks back, along with a rabble of other endjineers, I was fortunate enough to attend NDC London. This wasn't my first time at an NDC conference - in fact, my previous outing was to Oslo to experience the "original" flavour of NDC back in 2018. That was extremely fun and packed with so many amazing talks. NDC London this year was no different! Here are my highlights (in no particular order):
OWASP Top Ten proactive controls - Jim Manico
This was a really interesting (and lively!) talk by Jim, who volunteers for the OWASP foundation and owns his own security company. He started by introducing the Open web application security project (https://owasp.org/), a not-for-profit foundation pushing for better internet security. It offers numerous open-source tools for structuring and evaluating the security of your code. A popular tool of theirs is an open source security/pen-test tool: https://www.zaproxy.org/, which was actually mentioned on a couple of other occasions during the conference.
Jim mentioned a number of security best-practices, including:
- Leveraging known and 'trusted' security libraries - you don't need to reinvent the wheel when it comes to security frameworks. Just make sure you perform your own due diligence on the library you're wanting to use, and when you've incorporated it, be sure to keep it up to date and constantly check for any known bugs etc. Using the OWASP dependency check can help with this.
- Secure database access - spot any problems with this email address:
ed'or'1'!='@endjin.com? No? Neither does the IETF - it is fully RFC compliant. But it's perfectly formatted for SQL injection, if you've designed your queries using string concatenation/tokenization. As many of you know, the way to get around this is by using a parameterized statement. Consider using static analysis tools to help discover SQL injection in your code. - Enforce access control - more specifically, use permission/claims based access control as opposed to role based access control. So your access enforcement points are features in data rather than a user's role. A user can call an endpoint if they possess the capability to perform the actions that the endpoint performs. This enables an easier architecture for multi-tenant apps, and shifts the access control down to the data layer.
Jim elaborated on many other proactive controls (7, funnily enough), all of which were illuminating, and a nice checklist to follow when you're designing your next application. See this page for more details on the OWASP Top Ten proactive controls.

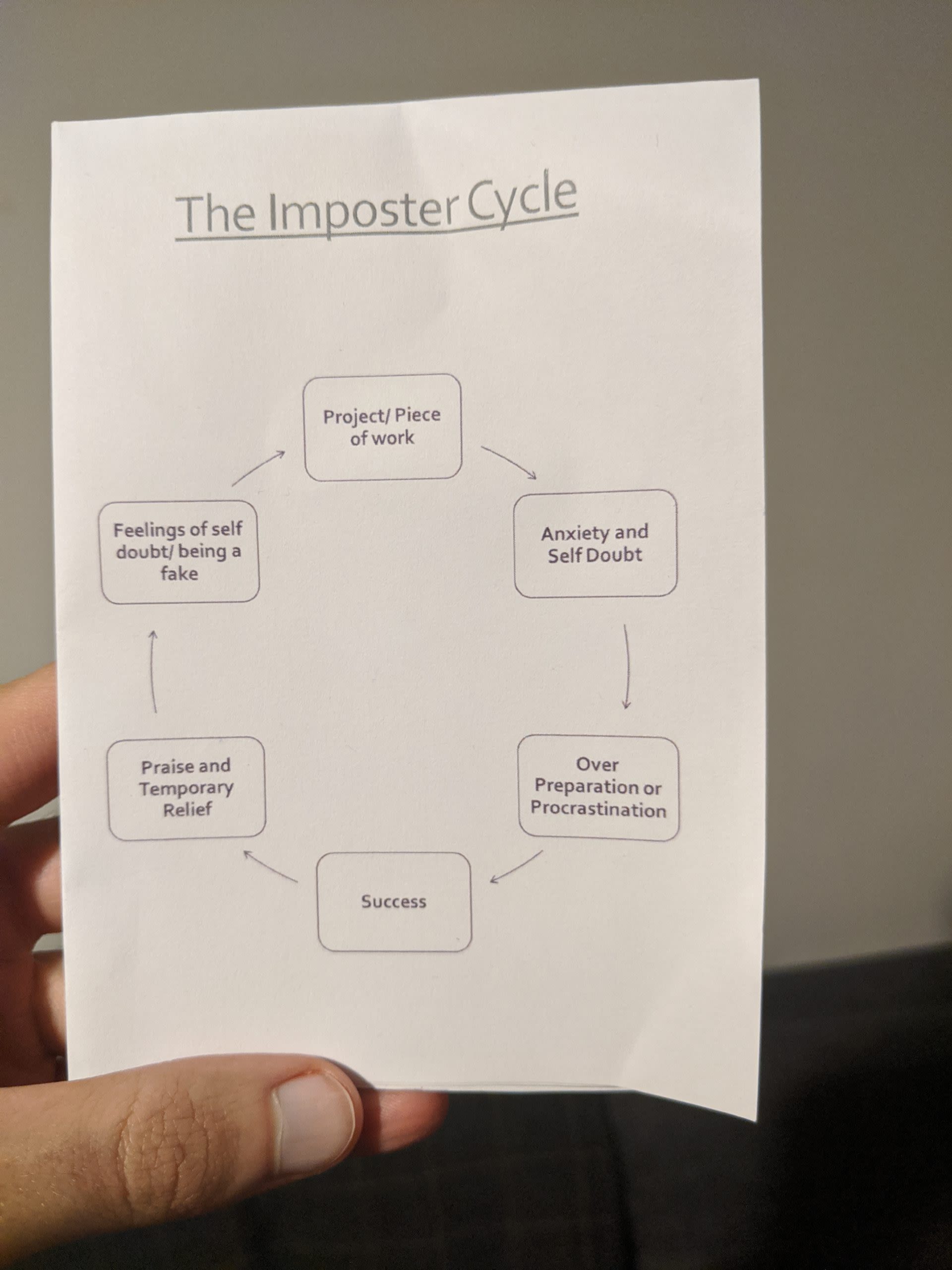
There's an Impostor in this room! - Angharad Edwards
Most people will feel like an impostor at some point in their career, but I suppose some people are more prone to it. I often feel like this, and feel much more comfortable by setting low expectations and exceeding them rather than setting higher (yet still reasonable) expectations and meeting them. Of course, this is something I need to work on - I can't go my whole career being pessimistic about what I can achieve. And this is not being "humble", but rather doubting one's abilities in certain scenarios.
The first portion of the talk was about identifying impostor syndrome-like thoughts, for which Angharad listed out numerous scenarios, both figurative and anecdotal. "I just won that piece of work for my company and everyone's congratulating me, but all I did was send an email that it took me 15 minutes to put together." "I've just got a promotion for high performance, but I've only been doing my job." Angharad used an example of when she needed to take a test on Agile. She spent the lead up to the exam thinking negatively and didn't even bother revising, until it was the week before. Then she went hell-for-leather for the last week and past with 97%. After the initial elation, she started having thoughts like "Well, I knew a lot of the answers from the various mock tests that I did, so it wasn't really hard..." "... and since I'd seen most of these questions, why couldn't I get 100%".
So the impostor thoughts won't stop, but there are ways to manage them and break the cycle. Angharad gave numerous methods, like a "Thought ladder", where you start by listing the thoughts you're currently thinking, and then think of the "nirvana" thought. Then you break that down into more bite-size thoughts, each progressing you up a step, and you strive for the next step. Very much like goal setting - but with thoughts, and a nice analogy.
Angharad also explained trivial methods like listing your positive qualities, time-boxing activities, thinking retrospectively and pragmatically. She had us write down statements on post-it notes which we'd use to compliment our best friend. We stuck these on the wall, and then she asked us to select a post-it note which had a statement which we'd never use to describe ourselves, probably because we didn't think they were remotely true. Once we all had our notes and had re-taken our seats, she had us all stare at the post-it note and say "Thank you" to the compliment, in unison. Slightly odd and awkward, but it's all for a reason!
It was certainly an interesting talk. I think what's most useful for self-doubters is knowing that you're not the only one. This knowledge, coupled with the tangible methods of breaking the vicious impostor cycle, will help tame those thoughts somewhat in the future (hopefully!)
How to code music? - Laura Silvanavičiūtė
This talk was just brilliant. Laura was an amazing speaker, and the talk was really engaging, funny and perfectly executed. Laura live-coded pretty much throughout the whole thing, and didn't put a foot wrong. Hugely impressive!
Essentially, using a simple sine wave, you can start building upon it (changing frequencies/amplitudes) to make sequences of sounds, and consequently music. Naturally, libraries have been built on top of this foundation, and more functionality has been exposed via various APIs/programming languages.
Laura showed us a number of tools and frameworks. The first was Gibber, a live coding environment for audiovisual performance and composition in the browser. Since its syntax is plain old JavaScript, it can be executed in any web page viewed inside a browser implementing a real-time audio API. Another way to "code music" is by using Tone.js, a framework built on top of the Web Audio API, providing numerous synths, effects and other abstractions. Finally, we were shown Sonic Pi, a language/tool designed for the creation and performance of music written in code, itself offering many synths, instruments, beats, looping capabilities, and pretty much anything you could wish for whilst creating music.
Laura treated us to numerous demos throughout the session - out of nowhere came Beethoven's "Für Elise", shortly followed by Queen's "Another One Bits the Dust", both of which were pleasant surprises for the much engrossed audience. Laura finished with a fantastic 5 minute original composition (at least I think it was an original!) Here's a short snippet:
It was a pleasure to present #howtocodemusic at #NDCLondon conference today!
— Laura Silvanavičiūtė (@laurasilvanavi) January 30, 2020
The audience was awesome! Many thanks for comming and sharing your feedback afterwards ❤️🤟#livecoding #javascript #sonicpi pic.twitter.com/Mw4wQomkux
If you get the chance to see this elsewhere, do! In fact, I believe Laura's talk has just been accepted for NDC Oslo, so if you're attending that, this session should be a no-brainer.
ML and the IoT: Living on the Edge – Brandon Satrom
As is common practice with talks at technical conferences, Brandon started out with an anecdote about his washing machine. (Whilst that sentence was intended as irony, it just so happens that Troy Hunt also spoke about washing machines in his talk "The Internet of Pwned Things" (which is worth checking out, too.)) The previous owner of Brandon's house, "Zeke", was a DIY enthusiast, with varying success. One of Zeke's projects was the installation of the kitchen appliances. The washing machine had begun to make strange noises, and would even cut out at specific points of the day, without fail. With time, Brandon and his partner could notice the issues compounding, to the point where they decided to get a brand new washing machine (instead of spending more money fixing the old one!)
However, what if they hadn't been around to monitor the state of the washing machine. What if Brandon and his partner ran a launderette with 50 washing machines. How could they detect when something might be about to go wrong with one of the machines? ML & the IoT can certainly help.
Whilst the washing machine anecdote framed up the talk nicely, Brandon more generally wanted to land 3 main points:
- Instead of "Machine Learning", it's actually "human teaching" – A human is teaching a machine how to do the right things correctly. Sure, the machine can go onto to compute things that humans can't possibly reproduce under the same conditions, but fundamentally it is the humans that are telling the machines what to do.
- Training is meant for the cloud – the development and training of a machine learning model is what the cloud is for. Whilst microprocessors are getting more powerful with each day, it makes much more sense to use the Cloud to develop and train the model, rather than trying to do this on the actual source device. The Cloud has unlimited compute power, and offers the most flexibility when it comes to having access to all the relevant dev tools, libraries etc.
- The real work of ML is in the IoT – i.e. the inference. It happens on the device on the "edge" and offers numerous advantages over doing the inference in the cloud. The volume of IoT devices and their corresponding data is ever-increasing. Of course, the cloud will always increase to meet demand. But the pipes that connect the IoT devices and the Cloud is where the constraints usually come. So not having to send all telemetry to the cloud means that we won't get throttled by the possible throughput. The speed of inferences when doing the inferencing in the device is obviously quicker than going via the cloud. The mere egress and ingress of data over a network adds (potentially critical) overhead to the whole process, so performing the inferencing on the device makes the round-trip to the Cloud redundant. Finally, and potentially most significantly, there's inherent privacy when doing the inference in the device. No need to send all data up to the cloud for the processing, with the chance of some of it being intercepted/lost along the way. Data stays where it is and gets processed right there.
Brandon justified these three main points, interspersing some cool demos of mood and motion detection algorithms he'd created to show the power of ML on the edge. Tying it back to the washing machine - one day (and this day might have already come), the devices sitting inside our washing machines will have built-in machine learning and be able to predict when meaningful events may occur. Better still, we may be able to customize the devices sitting within our washing machines so we can generate our own insights. You know, if that's something you have the desire to do. All in all, a very intriguing session.
Common API Security Pitfalls – Philippe De Ryck
In the session abstract Philippe said it was usually a popular talk – and this time was no different. To a packed room, Philippe presented an extensive list of common mistakes people make when implementing APIs. Here's my pick of the bunch:
Over-exposing API Data
Don't presume that because you're blurring an image in the client, an attacker won't be able to speak directly to the API to get that same image. In general, "never rely on client-side data processing or filtering to hide information. Always assume an attacker has full access to all API endpoints". Philippe used the example of being able to access a premium feature of Tinder by hitting the API directly, despite the account not being a premium account.
Lack of proper authorization
Which is inherently linked to the above, although from a different perspective. "Always complement an initial authentication check with appropriate authorization checks." Authentication – is this person who they say they are? Authorization – is this person allowed to do what they're trying to do? You might well know who a person is (maybe, in the Tinder example, they have a free Tinder account and therefore Tinder knows who they are), but that doesn't necessarily mean they can do something they try to do (obviously). It's common that APIs only check authentication status, but not which user is authenticated. This becomes a problem when, for example, the API has been designed to use predictable identifiers to enumerate resources. If my user id is 1234, and I hit the /api/users?id=1234 path, I should see some results. But I should not necessarily be able to see /api/users?id=1235 – and if I can, there may be a security hole. This point was also pointed out in Troy Hunt's "The internet of pwned things" on Thursday.
Philippe delved into many other pitfalls, from rate limiting to SQL injection. All very valid points, and food for thought for when you next implement an API.
Combatting illegal fishing with Machine Learning and Azure - for less than £10 / month – Jess Panni & Carmel Eve
Last but certainly not least, we have Jess and Carmel's talk based on a recent project of ours. We re-architected an on-premise solution to the cloud, using a serverless architecture with near real-time analysis for just a pittance a month! Look at this for more detail, and make sure you check out the NDC video recording once its made available!

To conclude
Whilst I haven't been to that many conferences in my career thus far (and therefore have little to compare NDC to), I can pick no faults with the conference at all. It was brilliant in Oslo, and brilliant in London. There are so many top-quality speakers and sessions - the most annoying thing is having to decide on which talk you're going to attend at each time slot! The food is also lovely, but that shouldn't necessarily be a deciding factor :) I look forward to attending another NDC event in the future!




