C# 8.0 nullable references: inferred (non-)nullness


C# 8.0's most ambitious feature, nullable references, has a mission: to help find problems in our code.
In this post, I'm going to talk about an aspect of nullable references that helps the compiler to minimize spurious warnings without also missing opportunities to identify real problems.
To compile our code, the C# compiler must form a deep and subtle model of what our code does. The essential idea underpinning nullable references is the same idea that underpins static typing, definite assignment rules, and all other forms of compile-time checking: since the compiler has to build up this model, why not use it to check our work?
If the compiler can deduce that there's a problem in our code, better for it to tell us now than for us to find out only when it starts causing trouble for our customers.
A nullable variable might be knowably non-null
One of the more subtle aspects of nullable references is that the compiler has two different notions of nullability. This can produce apparently contradictory answers to the question "is this nullable?"
That may sound messed up, but it's actually one of the most important aspect of this language feature—it makes it much easier for developers to use nullable references than it otherwise would be.
The obvious notion for nullability is the one you can see by looking at the declaration. Any field, variable, property, or parameter in an enabled nullable annotation context (see previous blog, but in short, anywhere you've enabled the language feature) can indicate whether it is meant to be nullable or not with the presence or absence of a ?. (If it's a variable, you might not be able to be able to tell by looking at it, because someone might have used var, but really, what kind of monster does that?)
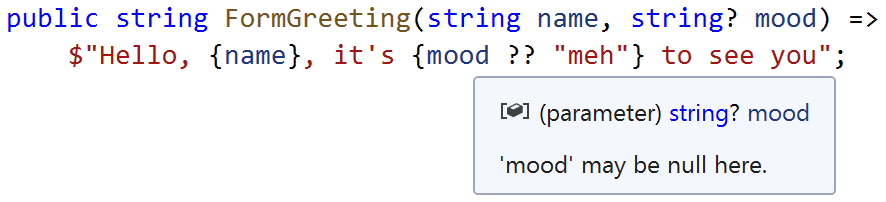
For example, we can see that this method expects the first argument to be non-null, and that it is able to cope with the second argument being null:
public string FormGreeting(string name, string? mood) => $"Hello, {name}, it's {mood ?? "meh"} to see you";
But this is not the whole story.
The compiler maintans a second notion of nullability which, if you're using Visual Studio, is visible in the tooltip you get if you mouse over a variable. (In fact the compiler calculates this form of nullability for any expression, but since expressions may be formed from other expressions, it's not always possible to mouse over them.)
But aren't they always the same? Not necessarily:

As you can see, my input parameter is of type string?, a clear statement that callers are allowed to pass a null argument. But the compiler has correctly determined (as reported through the tooltip) that it is not null when we are inside the body of the if statement.
This is inferred nullness (or, in the 2nd screenshot, inferred non-nullness). The compiler has a set of rules it uses to analyze code and these can sometimes determine that a particular expression is definitely not null.
If the expression in question is a simple use of a variable, then as the screenshot above shows, sometimes the compiler will infer that at that particular point in the code, the variable will not be null even though its declaration indicates that sometimes it may be null.
This analysis is very helpful because it often avoids the need to use the null forgiving operator to silence compiler warnings. There are situations where it is necessary to declare a variable as nullable because there are circumstances in which it may be null, but there will be some parts of the code where we can be confident that it will not be null. A very common example occurs when using a dictionary:
public void UseDictionary(string key, IDictionary<string, string> dictionary)
{
if (dictionary.TryGetValue(key, out string? value))
{
Console.WriteLine("String length:" + value.Length);
}
}
The out argument I've passed to TryGetValue needs to be nullable, because in the case where the dictionary contains no entry for the key, it can only set this to null. But if there is an entry, I don't want to get a compiler warning when I write value.Length. In general you'd expect one because value here is a string?, indicating it could contain null. But even with nullable warnings fully enabled, this code compiles without warnings on .NET Core 3.1 or .NET Standard 2.1.
You will get a warning if you try the exact same code on .NET Standard 2.0, or older versions of .NET. The reason we don't get warnings when using the latest .NET class libraries is that TryGetValue method has been annotated:
bool TryGetValue(TKey key, [MaybeNullWhen(false)] out TValue value);
That [MaybeNullWhen(false)] tells the compiler that if the method returns false the output value argument may be set to null. But when it returns true, it will be non-null, which is how the compiler knows that it's safe to write value.Length inside the if body.
The compiler doesn't just rely on attributes such as these. It can also work things out for itself, e.g.:
public void ShowLength(string? value)
{
if (value != null)
{
Console.WriteLine(value.Length);
}
else
{
Console.WriteLine("No string supplied");
}
}
Here, the compiler sees that we've explicitly compared the value with null so it knows that if execution enters the body of the if statement, value will not be null. And that's why in this example we won't see a warning for value.Length even though the declared type for value is nullable.
Slightly surprisingly, this also works in reverse. This next example produces a warning that we are deferencing a potentially null variable, even though the variable has been declared as non-nullable:
public void ParanoidAndWrong(string value)
{
if (value == null)
{
Console.WriteLine(value.Length);
}
}
That's contrived, but more generally, it is sometimes useful to be able to test an apparently non-nullable variable for nullness, because C# cannot make strong guarantees about nullable references.
For example, your code might be invoked by code that does not have nullable warnings enabled. Or indeed it might be called by code that has simply chosen to override the compiler's inferences.
For example, we can always use the null forgiving operator, or "dammit" operator as it's sometimes known. This takes the form of an exclamation mark on the end of an expression, and as this example shows, we're allowed to use it even when the expression is self-evidently null:
string x = null!;
This is occasionally useful, believe it or not. If you want to write a test verifying whether you correctly handle a null being passed where non-null is required, this lets you do it without causing compiler warnings.
Note that if you use the null forgiving operator on a variable, this feeds into the compiler's inference, and it will treat that variable as knowably non-null thereafter (until something happens that could modify the variable).
This means that if you find yourself needing to use this operator, it's often enough to add it just once, and it may cause all subsequent warnings for that variable to go away.
So nullability inference is not in any way a guarantee. But it is very useful: it means the compiler can determine when it is appropriate to provide warnings, and when it's safe not to. Without this inference mechanism, C# 8.0's nullable warnings feature would either produce a lot more false positives, or a lot more false negatives.



