Testing Power BI Dataflows using SpecFlow and the Common Data Model


Power BI solutions are inherently difficult to test due to the lack of available testing frameworks, the lack of control over UI rendering, and encapsulation of business logic within the underlying service.
However, like any application, the need to validate business rules and security boundaries is important, as well as the need for ensuring that quality doesn't regress over time as the solution evolves. Data insights are useless, even dangerous, if they can't be trusted, so despite the lack of "official support" or recommended approaches from Microsoft, endjin treat Power BI solutions just as any other software project with respect to testing - building automated quality gates into the end to end development process.
In subsequent posts, I'll discuss the approach we have taken to test the reports themselves, validating the calculations and data in the underlying tabular models. However, this post looks at Dataflows, which were introduced into the Power BI platform in 2019 as a way to centralise and reuse data preparation steps, allowing standardised access to source data across reports.
Testing Dataflows?
It's fair to say that, at first glance, Dataflows are hard to test too - whilst there is Dataflow support through the REST API, this is primarily targeted at the management of Dataflows, for example triggering a refresh, which doesn't help from a testing perspective.
However, there is one thing that is possible through the API that is the key to defining a comprehensive testing approach. The Dataflow definition is stored as a .json document, which can be exported through the API, or downloaded from the Power BI UI.
In both cases, the model.json contains information about the Dataflow schema - this includes the Entities that have been modelled, and the information about how the data has been partitioned in the underlying storage.
By interrogating the schema manifest and validating it against a known state, it is possible to assert that the Dataflow definition is as expected. If the data can be retrieved too, then the successful execution of the Dataflow can also be asserted (i.e. that the data source credentials are valid, and the refresh schedules are in place etc).
The rest of this post expands on this approach to testing Dataflows, outlining the various aspects that make it possible and providing a recommendation on what should be tested.
Common Data Model (CDM)
Under the covers, Dataflows store metadata and data in the Power BI service using the Common Data Model, which provides a standardised way to document and retrieve data models across various different data platform services in Azure and Office 365. Knowing this helps us to understand the schema manifest (the model.json file) better, as it's a well defined and documented format. However, it's still a lengthy and complex JSON document and any tests written against it will need to understand and parse the manifest.
CDM SDK
However, we're not starting from scratch - Microsoft are working on client SDKs for the Common Data Model, and that work can be found in the Microsoft/CDM GitHub repository. The repo contains various different pieces, including documentation, samples and SDK libraries for use in custom applications for C#, Java, Python and Typescript.
The C#/.NET SDK in particular is usable, but needs compiling from source as there's no NuGet package available (yet). But, downloading the solution and compiling your own .dlls (or just including the source) is easy enough to get going in your test project. This means we can work with a strongly typed SDK for accessing and navigating the schema manifest, which starts to make testing the Dataflow definition easier.
The first sample in the repository, called "Read Manifest" contains a C# console app that navigates the entire schema, reading each Entity definition and outputting the metadata. It's a great starting point for understanding how to use the SDK.
Accessing the data
By default, data used with Power BI is stored in internal storage provided by Power BI. This means that, although we can export the model.json through the Power BI API or download it from the UI, we can't use it to access the data itself. Navigating the schema manifest, each Entity contains a list of data partitions, each of which has a location property, which looks something like this:
"location":"https://wabiuksbprcdsap1.blob.core.windows.net:443/7a56924a-a1ea-4361-8bc1-c3bf1980e430/<EntityName>.csv?snapshot=2020-04-09T17%3A28%3A06.5018725Z"
Trying to hit that URL in a browser returns an HTTP 404 ResourceNotFound error - probably as this isn't a supported way to access this data (i.e. directly from outside the Power BI service).
However, in 2019, a preview feature was announced that allows you to store the Power BI Common Data Model output from your Dataflows in your own Azure Data Lake, rather than inside the Power BI service itself. By storing your Dataflows in your organisation's Azure Data Lake Storage account, you have more control and flexibility over authorisation and security boundaries, as well as more options for exposing and reusing that data across your organisation (i.e. non-Power BI scenarios). But it also creates new opportunities for testing, as if we now control where the output is stored, we have control over how it is accessed.
So, by enabling this preview feature, we can get around the limitation in not being able to access the data, as the data partitions now point to locations in a Data Lake that we own. It also makes accessing the model.json easier too, as this gets stored in the Data Lake as well, as per the description of how the CDM folders are structured in the documentation.
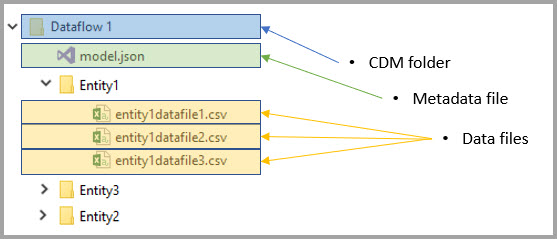
The .NET CDM SDK includes an adapter for working with Azure Data Lake as the underlying storage repository, and the samples contain the code needed to connect using either a storage account key, or service principal username and password. So, with this, all the tests can read directly from Azure Data Lake - to retrieve the Dataflow schema manifest, and traverse it to retrieve the data out of Data Lake for each of the Entity definitions to validate that everything is ok.
Executable specifications
Now that we know that we can retrieve the Dataflow schema manifest and use it to access the metadata about the Entity definitions and the stored data itself, the final question is how to structure the tests themselves.
We prefer and recommend executable specifications rather than unit tests - describing the behaviour of the system in easily understandable business language, and we can apply this approach to testing Dataflows quite easily. In a .NET test project. this probably means using SpecFlow - a .NET test runner implementation of the BDD Gherkin language. Taking a "feature-per-entity" approach, an example specification for an Orders Entity in a larger Sales Dataflow might look like this:
The feature covers three scenarios - validating the schema of the Entity is correct, validating that all the data is present using the row count, and validating the specific field values of a sample of the first 5 rows.
Behind the feature, the C# steps connect to the Data Lake storage using the adapter in the CDM SDK, retrieve the Entity definition from the model manifest to validate its properties, and finally follow the paths returned for the data partitions to load and parse the data from storage to assert that it matches the expected results.
And what's great is that this feature is entirely reusable as a template for other Entities as they're added, as all of the steps are parameterised, or driven from the data tables.
Recapping the approach
Putting it all together, a comprehensive approach to testing Power BI Dataflows can be achieved by:
- Enabling the Azure Data Lake integration (preview) feature, so that Dataflow output is stored in your own Data Lake and can be accessed programmatically
- Using the Common Data Model (CDM) SDK, including the Azure Data Lake adapter, to connect to the CDM output to navigate and test the Entity schema definitions
- Follow the data partition URLs in the CDM manifest to retrieve the data for each Entity from the Data Lake, to test that the Dataflow has run successfully
- Write executable specifications to test the Dataflow definition and data at the Entity level - these can be run manually or as part of an automated DevOps pipeline
Conclusion
Whilst testing Power BI Dataflows isn't something that many people think about, it's critical that business rules and associated data preparation steps are validated to ensure the right insights are available to the right people across the organisation. Whilst there's no "obvious" way to test Dataflows, this post outlines an approach that endjin has used successfully to add quality gates and build confidence in large and complex Power BI solutions.